Teil II: Parallele MPI - Version des TOV-Programms mit geordneter Ausgabe in eine Datei und variabler Zustandsgleichung
Diese Version entspricht der OpenMP-Version Version 2.6), benutzt jedoch MPI und nicht OpenMP zur Parallelisierung und kann somit auch auf heutigen Großrechneranlagen, die über eine hohe Anzahl von Rechenknoten mit einer Vielzahl von CPU-Kernen verfügen, parallel ausgeführt werden. Wichtig ist nun, dass man das Programm mit dem folgenden Befehl compiliert: 'mpic++ TOV_parallel_omp2_eos_time.cpp' und das Programm mit 'mpirun -np 6 ./a.out' ausführt ('-np 6' ist hier nur ein Beispiel und die Zahl 6 gibt die Anzahl der Prozesse an).
Struktur des parallelen MPI-C++ Programms

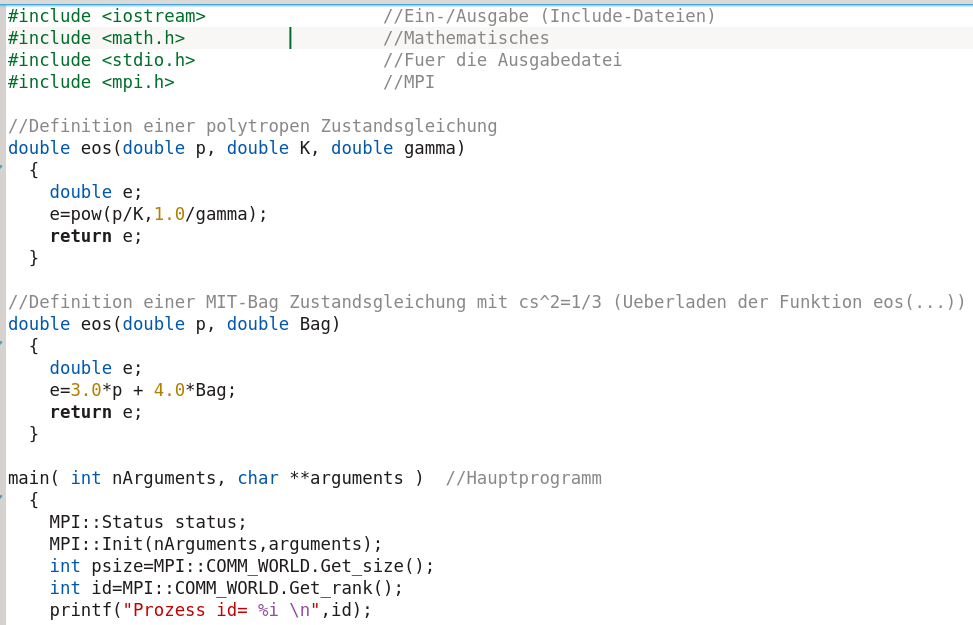
Beim Ausführen des Programms spezifiziert der User mit wie vielen Prozessen er das Programm ausführen will (z.B. mit sechs Prozessen 'mpirun -np 6 ./a.out'). Ab diesem Zeitpunkt läuft das Programm mit sechs Prozessen, denen man im Laufe der weiteren Programmabfolge unterschiedliche Aufgaben zuweisen sollte, damit sie nicht alle das gleiche Ausführen. Die in der letzten Zeile angegebene Terminalausgabe erfolgt z.B. bei sechs Prozessen sechs mal; die Variable 'id' bezeichnet hier die fortlaufende Nummer des Prozesses (0,1,..,5).

Eine sinnvolle Aufteilung der einzelnen Aufgaben des TOV-Programms auf die jeweiligen Prozesse kann man z.B. realisieren, indem die 150 (anz=150) zu berechnenden Neutronensterne auf die jeweiligen Prozesse aufteilt werden. In dem die for-Schleife von einem prozessabhängigen Startwert anfängt und in Schrittweiten 'psize' (Anzahl der Prozesse, hier z.B. 6) geht, rechnet jeder Prozess einen anderen Stern aus. Prozess 'id=0' rechnet z.B. die Sterne 'i=0,6,12,18,..' und Prozess 'id=4' rechnet z.B. die Sterne 'i=4,10,16,22,..' aus. Im Gegensatz zu den Threads in der OpenMP-Version wissen die einzelnen Prozesse der MPI Version nichts über die Berechnungen und Ergebnisse der anderen Prozesse, so dass die Werte der berechneten Ergebnisse übermittelt werden müssen - dies geschiet mit einem 'MPI::COMM_WORLD.Send(...)'-Kommando. In dieser Version senden alle Prozesse ihre Ergebnisse an Prozess mit 'id=0'.
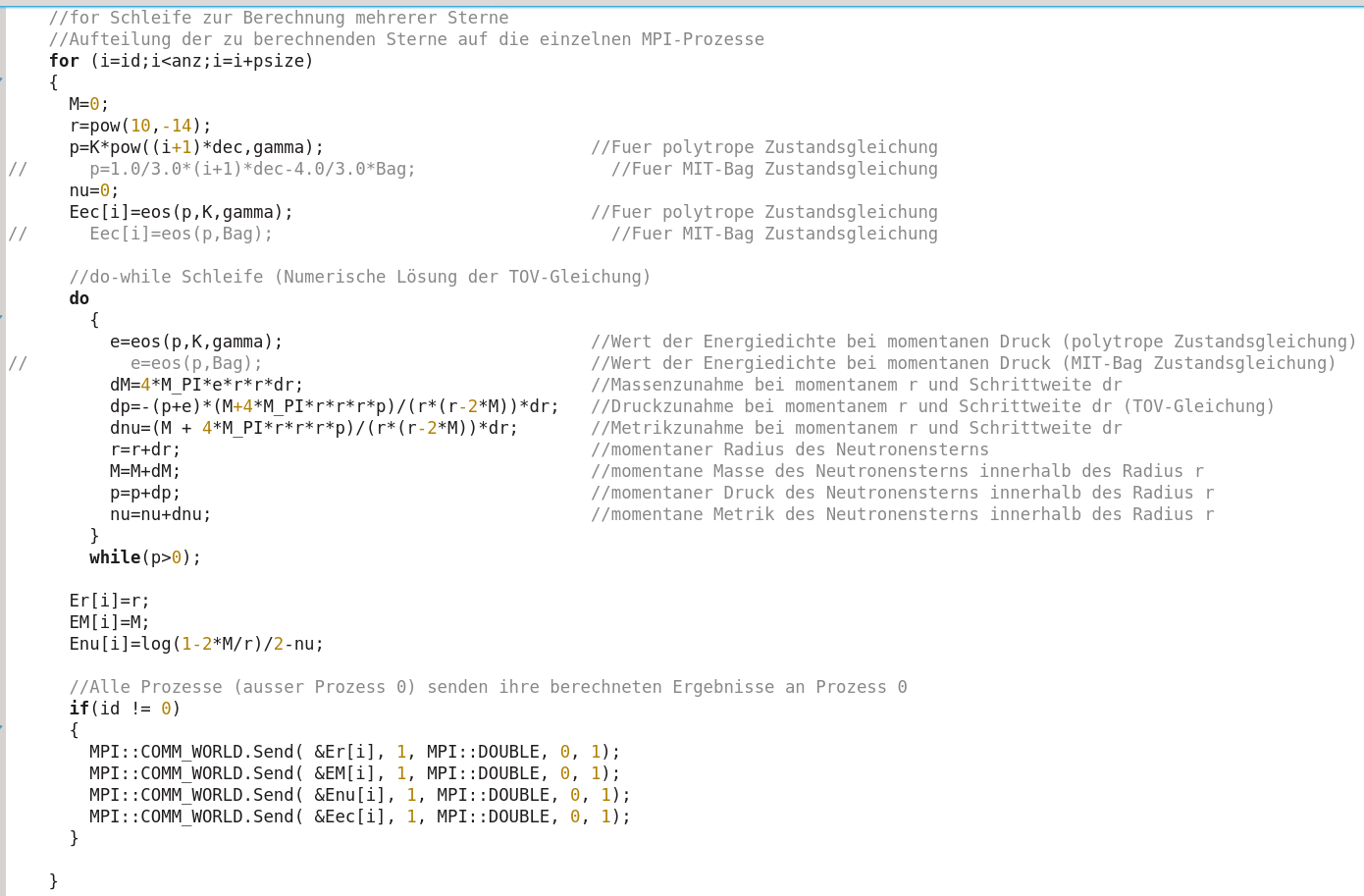


Prozess '0' empfängt dannach alle Daten und gibt diese in die Ausgabedatei aus.

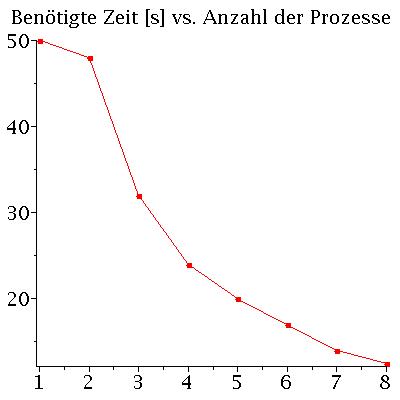
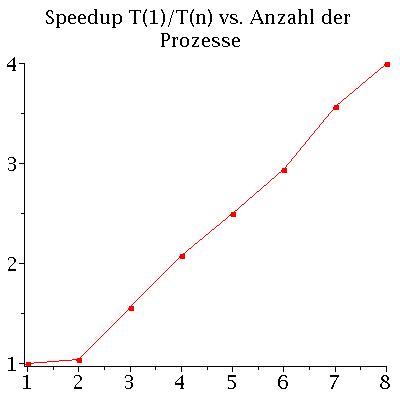
Performance des parallelen OpenMP-C++ Programms
Die Performance eines parallelen Programms kann mit unterschiedlichen Größen quantisiert werden. Man definiert z.B. die beötigte Zeit T des Programms als Funktion der zu Verfügung stehenden CPU-Kerne n mit T(n), das sogenannte SpeedUp S mit S(n)=T(1)/T(n) und die Effizienz E des Programms mit E(n)=S(n)/n. Die fogenden Abbildungen zeigen die beötigte Zeit T(n) und den SpeedUp S(n) des MPI - C++ Programms auf einem Laptop (Quadcore-i7 (Intel(R) Core(TM) i7-4710HQ CPU @ 2.50GHz) mit effektiv 8 Kernen). Die Abbildungen stellen die Ergebnisse einer Rechnung von 500 Neutronensternen mit einer Schrittweite von dr=0.000005 dar.