Musterlösung zum Übungsblatt Nr. 2
Musterlösung zur Aufgabe 1 (10 Punkte)
Das folgende C++ Programm stellt eine Musterlösung zur Aufgabe 1 dar:
// Musterlösung der Aufgabe 1 des Übungsblattes Nr.2 #include <iostream> // Ein- und Ausgabebibliothek #include <cmath> // Bibliothek für mathematisches (e-Funktion, Betrag, ...) #include <limits> // In dieser Bibliothek ist das Template std::numeric_limits enthalten using namespace std; // Benutze den Namensraum std int main(){ // Hauptfunktion float e_approx_1; // Deklaration der float Variable für den approximierten Wert der Zahl e double e_approx_2; // Deklaration der double Variable für den approximierten Wert der Zahl e unsigned long n = 10000; // Deklaration der langen ganzen Zahl Variable n und Initialisierung e_approx_1 = pow(1+1.0/n,n); // Berechnung des Folgengliedes bei gewähltem n und Übergabe des Wertes an die float Variable e_approx_2 = pow(1+1.0/n,n); // Berechnung des Folgengliedes bei gewähltem n und Übergabe des Wertes an die double Variable // Terminal Ausgabe printf("Die Approximationen der Eulerschen Zahl e, unter Verwendung von n = %li, lauten: \n",n); printf("%24s %24s \n","float-Approximation","double-Approximation"); printf("%24.20f %24.20f \n",e_approx_1, e_approx_2); // Terminal Ausgabe der appr. Werte für e printf("%24s %24s \n","Fehler float","Fehler double"); printf("%24.20Lf %24.20Lf \n",M_El - e_approx_1, M_El - e_approx_2); // Terminal Ausgabe der Fehler printf("%24.16Le %24.16Le \n\n",M_El - e_approx_1, M_El - e_approx_2); // Fehler in exponentieller Schreibweise // Neuer, größerer Wert von n, neue Berechnung, Terminal Ausgabe n = 1.0e+8; //Entspricht n=10^8 e_approx_1 = pow(1+1.0/n,n); e_approx_2 = pow(1+1.0/n,n); // Terminal Ausgabe printf("Die Approximationen der Eulerschen Zahl e, unter Verwendung von n = %li, lauten: \n",n); printf("%24s %24s \n","float-Approximation","double-Approximation"); printf("%24.20f %24.20f \n",e_approx_1, e_approx_2); // Terminal Ausgabe der appr. Werte für e printf("%24s %24s \n","Fehler float","Fehler double"); printf("%24.20Lf %24.20Lf \n",M_El - e_approx_1, M_El - e_approx_2); // Terminal Ausgabe der Fehler printf("%24.16Le %24.16Le \n\n",M_El - e_approx_1, M_El - e_approx_2); // Fehler in exponentieller Schreibweise /* Neuer, größerer Wert von n, neue Berechnung, Terminal Ausgabe * Das Maschinen-Epsilon eines Gleitkommazahlen-Typs stellt die Differenz zwischen 1 und dem kleinsten darstellbaren Wert größer als 1 dar. * Da innerhalb der Folge (1+1/n)^n bei sehr großem n eine Zahl zu 1 addiert wird, die kleiner als das Maschinen-Epsilon ist, markiert * die ganze Zahl 1/epsilon die Zahl, bei der wohl die beste Approximation vorliegt */ n = 1.0/numeric_limits<double>::epsilon(); e_approx_1 = pow(1+1.0/n,n); e_approx_2 = pow(1+1.0/n,n); // Terminal Ausgabe printf("Die Approximationen der Eulerschen Zahl e, unter Verwendung von n = %li, lauten: \n",n); printf("%24s %24s \n","float-Approximation","double-Approximation"); printf("%24.20f %24.20f \n",e_approx_1, e_approx_2); // Terminal Ausgabe der appr. Werte für e printf("%24s %24s \n","Fehler float","Fehler double"); printf("%24.20Lf %24.20Lf \n",M_El - e_approx_1, M_El - e_approx_2); // Terminal Ausgabe der Fehler printf("%24.16Le %24.16Le \n",M_El - e_approx_1, M_El - e_approx_2); // Fehler in exponentieller Schreibweise }
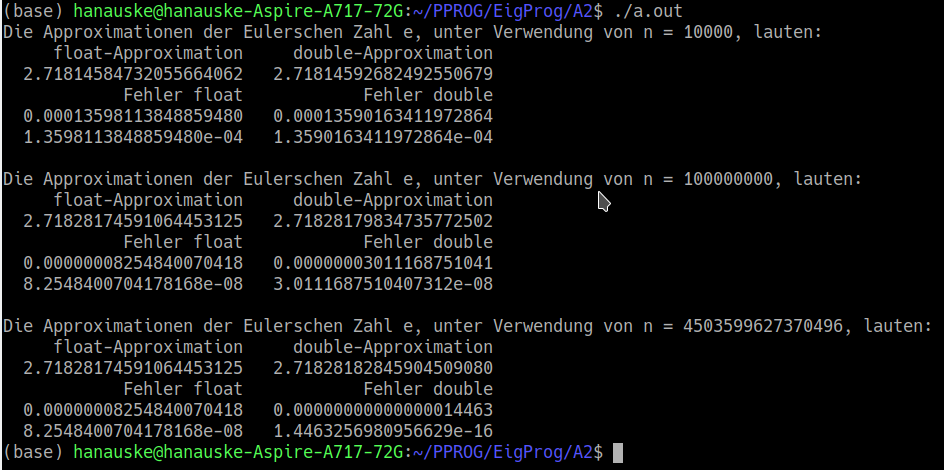
Zunächst werden die nötigen Bibliotheken eingebunden, wobei man <iostream> für die Ausgabe, <cmath> für mathematische Definitionen (z.B. den Wert der Eulerschen Zahl e) und <limits> für definierte numerische Grenzwerte (näheres siehe später) benötigt. Die darauf folgende Zeile ( using namespace std; ) benötigt man nicht für die Ausgabe, sondern das später, in <limits> enthaltene Template "numeric_limits" ist ein Teil des Namensraums "std". Danach werden die zwei reellwertige Variablen der Datentypen float und double deklariert, die die zwei approximierte Werte der Eulerschen Zahl $e$ darstellen sollen ("e_approx_1" und "e_approx_2"). Dann wird die lange natürliche Zahl $n$ deklariert und gleichzeitig mit dem Wert $10000$ initialisiert. Den zwei reellwertigen Variablen wird dann der Zahlenwert der Folge $\left( 1 + \frac{1}{n} \right)^n$ zugewiesen und die berechneten Werte werden in einer formatierten Ausgabe auf 20 Nachkommastellen genau ausgegeben. Zusätzlich wird auch der Fehler (${\cal F} = e - e_{approx}$) in normaler Kommaschreibweise und exponentieller Schreibweise ausgegeben. Dann wird der Wert von n auf $n = 10^8$ erhöht und die neu berechneten Werte werden wieder ausgegeben. Man erkennt (siehe später in der Terminalausgabe des ausgeführten Programms), dass die approximierten Werte der Eulerschen Zahl bei diesem erhöhten $n$ besser werden und der Fehler kleiner wird.
Wie genau kann man die Zahl $e$ mittels der definierten double-Variablen bestimmen? Man könnte nun denken, dass man einfach die größt mögliche Zahl für $n$ benutzt, da sich ja der exakte Wert von e im Limes $\lim \limits_{n \to \infty}$ ergibt. Die größt mögliche long Zahl beträgt $n_{max}:=9223372036854775807$, jedoch setzt man diese für $n$ ein und berechnet die approximierten Werte für e, erhält man keine sinnvollen Ergebnisse (man erhält als approximierte Werte nicht e, sondern 1). Dies liegt daran, dass innerhalb der Folge $a_n = \left( 1 + \frac{1}{n} \right)^n$ bei sehr großem $n$ eine Zahl zu 1 addiert wird, die kleiner als das Maschinen-Epsilon $\epsilon_M$ des double-Typs ist. Das Maschinen-Epsilon $\epsilon_M$ eines Gleitkommazahlen-Typs stellt die Differenz zwischen 1 und dem kleinsten darstellbaren Wert größer als 1 dar. Zwar ist der Zahlenwert $\frac{1}{n_{max}} = 1.08420217248550443401 \cdot 10^{-19}$ mittels einer double Variable ohne weiteres darstellbar (der kleinste Wert, der mit einer double-Variable darstellbar ist beträgt $2.22507385850720138309 \cdot 10^{-308}$), jedoch ist dieser kleiner als das Maschinen-Epsilon des double-Typs ($\epsilon_M=2.22044604925031308085 \cdot 10^{-16}$). Dies bewirkt nun, das der Ausdruck $\left( 1 + \frac{1}{n_{max}} \right)$ die Zahl 1 zurückgibt und die Potenz $1^{n_{max}}$ ändert daran auch nichts mehr. Nun versteht man, dass wohl die beste Approximation der Zahl e durch folgenden Ausdruck zu programmieren ist: $ \left( 1 + \epsilon_M \right)^\frac{1}{\epsilon_M}$. Die wohl beste natürliche Zahl ergibt sich somit durch den ganzzahligen Wert der Zahl $\frac{1}{\epsilon_M}$, was im nebenstehenden Programm durch die Zeile "n = 1.0/numeric_limits<double>::epsilon();" ausgedrückt wurde (der Wert für n berechnet sich zu $n=4503599627370495$). Kompiliert man das Programm und führt es im Terminal aus, so erhält man die links oben abgebildete Terminalausgabe.
Am Ende sollte sicherlich noch bemerkt werden, dass es sich bei dem Wert des berechneten Fehlers genau genommen nicht um den Rechenfehler zur wirklichen Eulerschen Zahl e ($2.7182818284590452353602874713526625...$) handelt, sondern um die Abweichung des approximierten Wertes zum long double-Wert M_El=$2.7182818284590452354281681079939403...$, welcher nur auf 18 Nachkommastellen genau ist.
// Musterlösung der Aufgabe 2 des Übungsblattes Nr.2 #include <iostream> // Ein- und Ausgabebibliothek #include <cmath> // Bibliothek für mathematisches (e-Funktion, Betrag, ...) int main(){ // Hauptfunktion double A_1 = 64.0/128; // Deklaration der double Variable für Aufgabe 2.1 und Initialisierung double A_2 = 2*M_PI/5; // Deklaration der double Variable für Aufgabe 2.2 und Initialisierung double A_3 = cos(M_PI/2); // Deklaration der double Variable für Aufgabe 2.3 und Initialisierung double A_4 = exp(pow(5.84,-12)); // Deklaration der double Variable für Aufgabe 2.4 und Initialisierung double A_5 = log(exp(1.1)); // Deklaration der double Variable für Aufgabe 2.5 und Initialisierung // Terminal Ausgabe auf 10 bzw. 20 Nachkommastellen printf("%-24s %-24s %-24s %-24s %-24s \n","Aufgabe 2.1","Aufgabe 2.2","Aufgabe 2.3","Aufgabe 2.4","Aufgabe 2.5"); printf("%-24.10f %-24.10f %-24.10f %-24.10f %-24.10f \n",A_1,A_2,A_3,A_4,A_5); printf("%-24.20f %-24.20f %-24.20f %-24.20f %-24.20f \n",A_1,A_2,A_3,A_4,A_5); }
Musterlösung zur Aufgabe 2 (5 Punkte)
Das nebenstehende C++ Programm berechnt die mathematischen Ausdrücke \[ \begin{equation} \frac{64}{128} \, , \quad \frac{2 \pi}{5} \, , \quad \hbox{cos}\left( \frac{\pi}{2} \right) \, , \quad e^{\left( 5.84^{-12} \right)} \, , \quad \hbox{ln}\left( e^{1.1} \right) \quad , \end{equation} \] und gibt die berechneten Werte auf 10 und 20 Stellen genau im Terminal mittels einer formatierten Ausgabe aus. Die Zahlenwerte wurden zunächst in fünf double-Variablen (doppelte Maschinengenauigkeit) gespeichert und danach mittels printf(..) ausgegeben. Kompiliert man das Programm und führt es im Terminal aus, so erhält man die links oben abgebildete Terminalausgabe.

// Aufgabe 3 des Übungsblattes Nr.2 // Drei Fehler und viele unschöne Ausdrücke #include <iostream> #include <cmath> int main(){ int n; n = 0; double a = 0; a = pow(2,n); cout < a << endl; n = n + 1; a = pow(n,2); cout << a << endl; n = n + 1; a = pow(n,2); cout << a << endl; n = n + 1; a = pow(n,2); cout << a << endl; }
// Aufgabe 3 des Übungsblattes Nr.2 // Drei Fehler wurden korrigiert #include <iostream> #include <cmath> using namespace std; // 1. Fehler int main(){ int n; n = 0; double a = 0; a = pow(n,2); // 2. Fehler cout << a << endl; // 3. Fehler n = n + 1; a = pow(n,2); cout << a << endl; n = n + 1; a = pow(n,2); cout << a << endl; n = n + 1; a = pow(n,2); cout << a << endl; }
// Musterlösung: Aufgabe 3 des Übungsblattes Nr.2 #include <iostream> using namespace std; int main(){ unsigned int n =0; cout << n*n << endl; ++n; cout << n*n << endl; ++n; cout << n*n << endl; ++n; cout << n*n << endl; }
Musterlösung zur Aufgabe 3 (5 Punkte)
Das ursprüngliche fehlerhafte Programm (linke Abbildung) lässt sich nicht kompilieren. Der erste Fehler liegt darin, dass der Ausgabebefehl "cout" verwendet wurde, ohne zuvor kenntlich zu machen, dass dieser sich im Namensraum der Standardbibliothek "std" befindet. Der zweite Fehler liegt in einer falschen Verwendung der Potenzfunktion. "pow(2,n)" bedeutet $2^n$ und nicht $n^2$. Der dritte Fehler liegt bei der erstmaligen Verwendung des Befehls "cout" (ein Kleinerzeichen zu wenig). Das auf der rechten Seite dargestellte Programm stellt die fehlerkorrigierte Version dar, und dieses lässt sich nun kompilieren und liefert nach der Ausführung auch richtige Ergebnisse (die Zahlenwerte der Folge $(a_n)_{n \in ℕ}$ mit $a_n := n^2$ für $n \in [0,1,2,3]$ werden richtig ausgegeben). Das Programm ist jedoch immer noch an vielen Stellen umständlich und nicht optimal programmiert. So kann man z.B. die getrennte Deklaration und Initialisierung der Variable $n$ in einer Zeile schreiben und es ist wohl genauer diese Variable als unsigned int-Typ zu deklarieren, da sie keine negativen Werte annehmen kann. Bei einer Berechnung von $n^2$ ist es vielleicht nicht unbedingt notwendig die "pow()"-Funktion zu verwenden und man kann einfach "n*n" schreiben; dies ist aber sicherlich eine Geschmacksache. Die verwendeten Inkrementierungen der Zahl n (n = n + 1;) ist zwar nicht falsch, aber schöner ist sicherlich die Verwendung des Inkrementierungsoperators "++n;". Die untere linke Abbildung zeigt eine Version eines verbesserten Programms.