complex-valued neural nets
- dtype=torch.cfloat
complex data type for tensors
:: for activities, weights, ... -
torch.matmul()
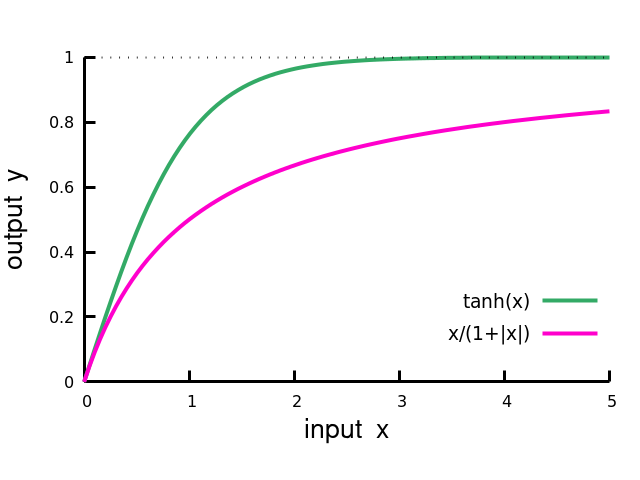
only between tensors with identical data types - non-linear units $\ g(z)$
- holomorphic $\frac{dg}{dz}$ exists
- non-holomorphic does not exist everywhere
- circular squatting (non-holomorphic)
:: extends dynamical range
- plane wave classification $\displaystyle \quad\qquad
\mathrm{e}^{ikx} \quad\to\quad \mathrm{e}^{ik}$
$k$ wavevector
$x$ linear data dimension
Copy
Copy to clipboad
Downlaod
Download
#!/usr/bin/env python3
#
# complex network, plane wave classification
#
import torch
import random
import math
import cmath # complex math
dataDim = 10
nLayer = 2 # two == one hidden layer
nData = 10
nBatch = nData
nEpochs = 20
nIter = nBatch*nEpochs
learningRate = 1.0e-2
print("# default data type: ", torch.get_default_dtype())
# default data type can be changed, but (yet) not to cfloat
class ComplexLayer(torch.nn.Module):
def __init__(self, dimOut, dimIn, zero_if_linear = 1.0):
super().__init__()
self.weights = torch.randn(dimOut, dimIn,
requires_grad=True, dtype=torch.cfloat)
self.bias = torch.randn(dimOut,
requires_grad=True, dtype=torch.cfloat)
self.zero_if_linear = zero_if_linear # zero for linear layer
def forward(self, x): # cicrular squatting
z = torch.matmul(self.weights, x) - self.bias
return z/(1.0+self.zero_if_linear*z.abs())
def update(self, eps): # updating parameters
with torch.no_grad():
self.weights -= eps*self.weights.grad
self.bias -= eps*self.bias.grad
self.weights.grad = None
self.bias.grad = None
#
# model, output layer is linear
#
allLayers = [ComplexLayer(dataDim, dataDim) for _ in range(nLayer-1)]
allLayers.append(ComplexLayer(1 , dataDim, zero_if_linear=0.0))
print("# allLayers : ", allLayers)
def model(x):
for iLayer in range(nLayer):
x = allLayers[iLayer](x)
return x
#
# generate data: plane waves
#
myData = torch.ones(nData, dataDim, dtype=torch.cfloat)
myValues = torch.ones(nData, 1, dtype=torch.cfloat)
delta_k = 2.0*math.pi/dataDim # 2\pi / length
for iData in range(nData):
qq = iData*delta_k # wave vector
ww = complex(math.cos(qq), math.sin(qq))
myValues[iData][0] *= ww # circular encoding
#
for iDim in range(dataDim):
zz = complex(math.cos(iDim*qq), math.sin(iDim*qq))
myData[iData][iDim] *= zz
if (1==2): # test output: data
for iDim in range(dataDim):
print(myData[1][iDim].item().real,
myData[1][iDim].item().imag)
if (1==2): # test output: targets
for iData in range(nData):
print(myValues[iData][0].item().real,
myValues[iData][0].item().imag)
#
# training loop
#
for iIter in range(nIter): # trainning loop
thisData = random.randrange(nData) # select random data entry
x = myData[thisData]
y = model(x) # forward pass
target = myValues[thisData][0]
loss = abs((target-y).pow(2)) # loss must be real
loss.backward() # summing over batch
#
if (iIter%nBatch==0): # updating
for iLayer in range(nLayer):
allLayers[iLayer].update(learningRate/nBatch)
print(f'{iIter:6d} {loss.item():8.4f}')