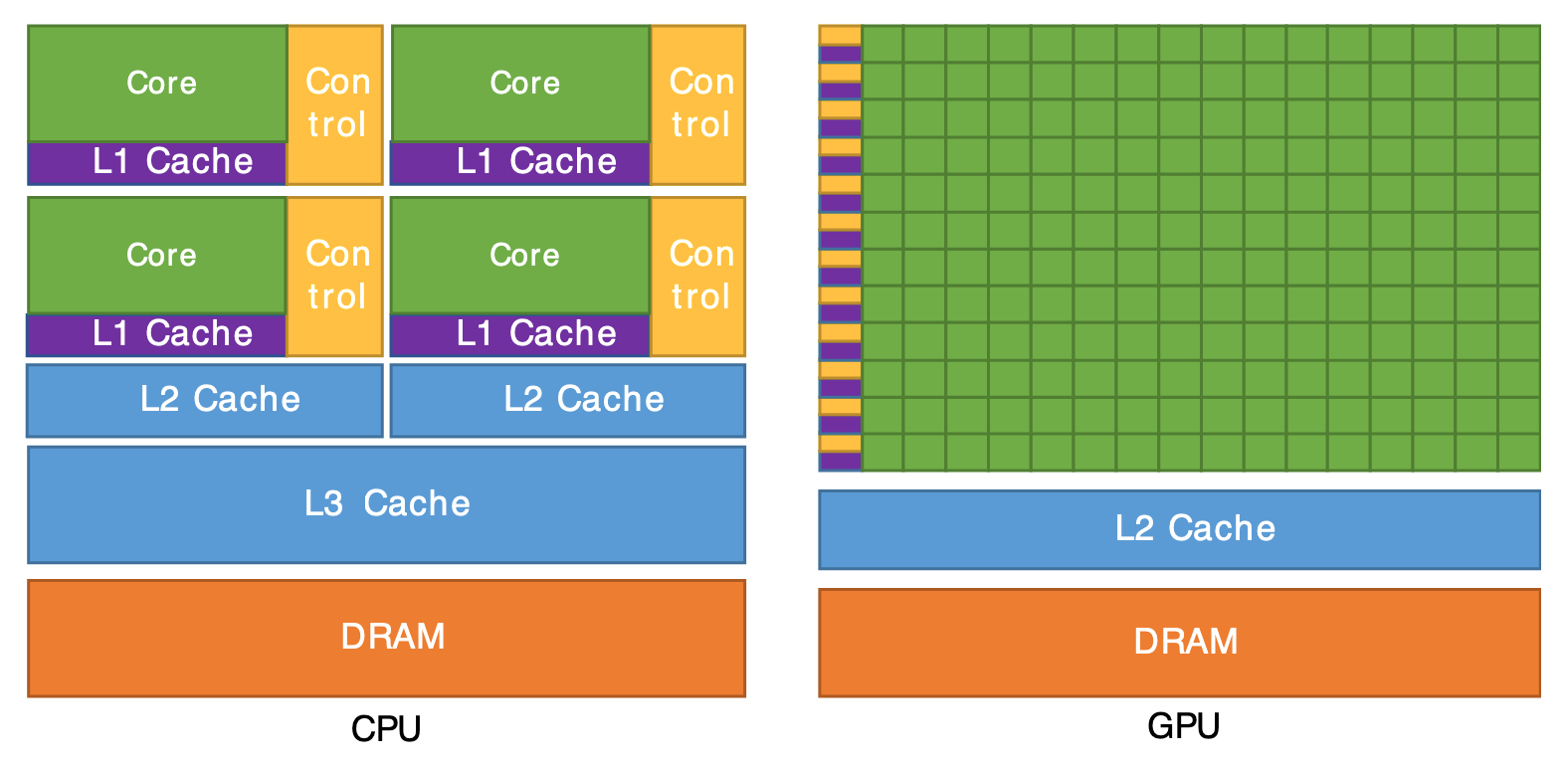
Machine Learning Primer -- Part III: Advanced Topics
Claudius Gros, WS 2025/26
Institut für theoretische Physik
Goethe-University Frankfurt a.M.
ML Trends / Scaling / Varia
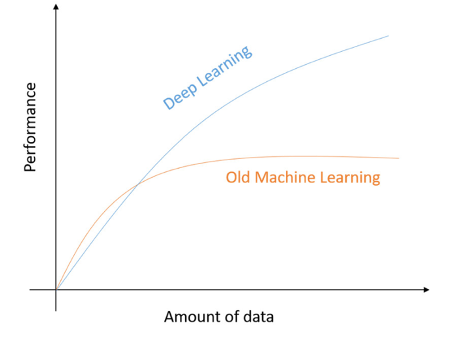
efficient learning
performance
complexity barrier
old/new ML: hard/soft
|
|
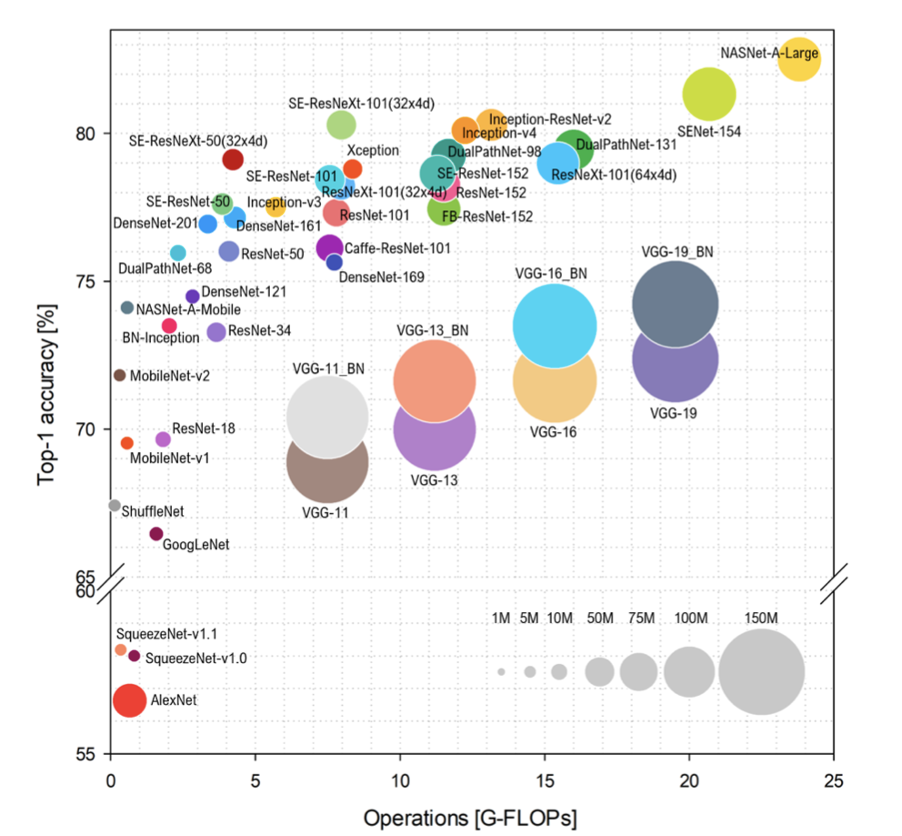
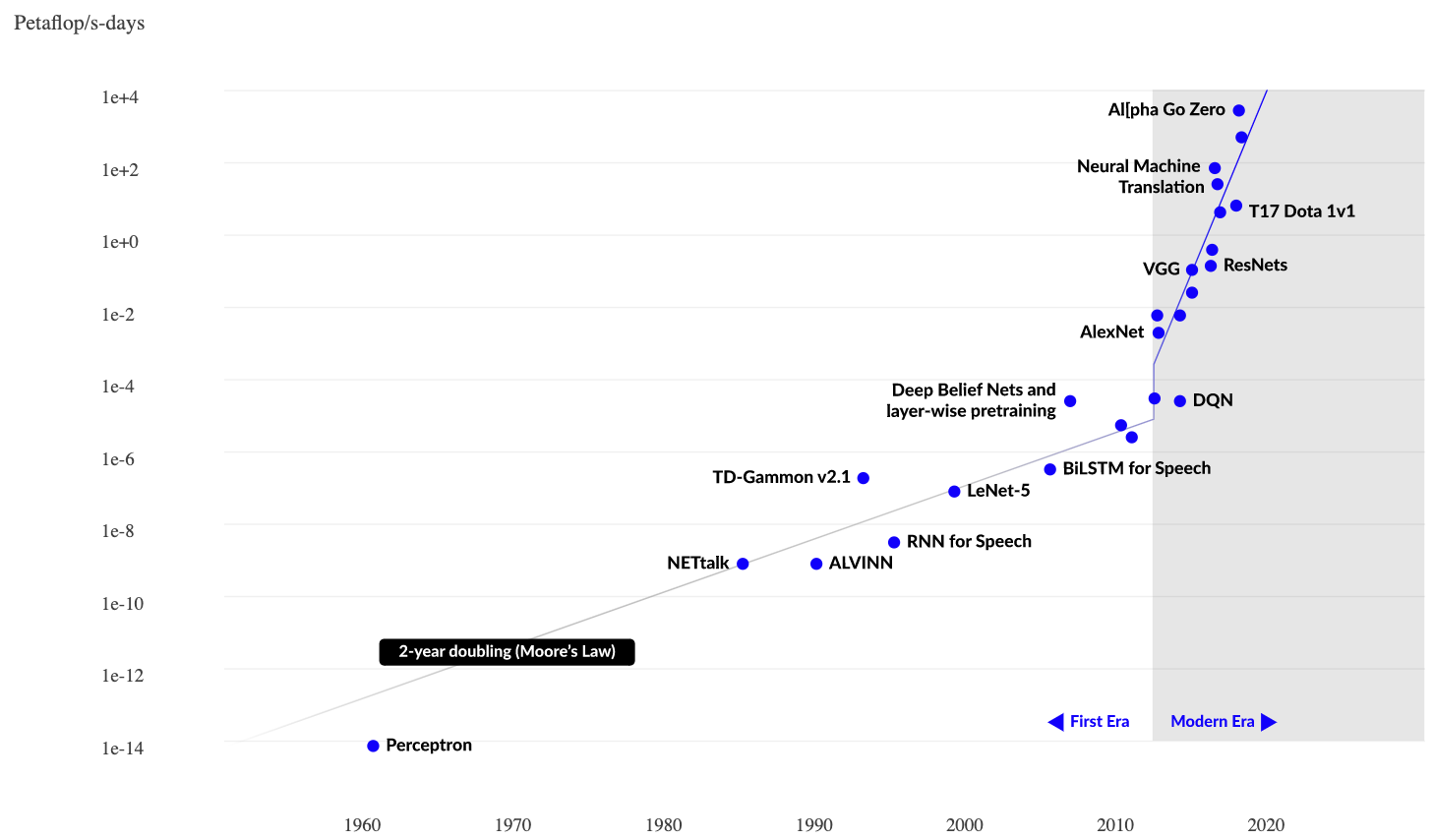
scaling
$$
\begin{array}{rcl}
\def\arraystretch{1.4}
\mathrm{N} &:& \mathrm{number\ model\ parameters} \\
\mathrm{C} &:& \mathrm{computing\ resources} \\
\mathrm{D} &:& \mathrm{dataset\ size}
\end{array}
$$
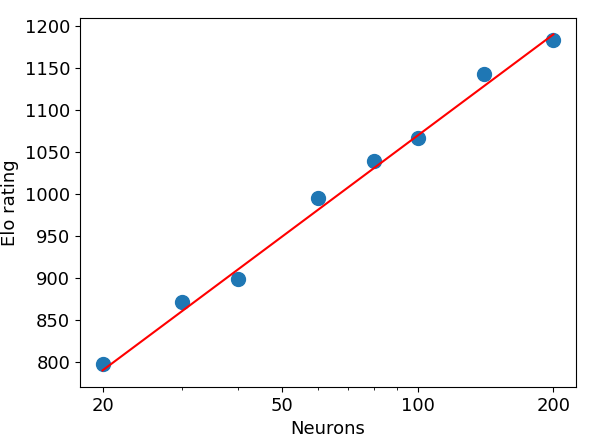
competitive games
two-player knapsack
- optimize total value when packing items with different (values,weights)
- $\alpha$-zero (state of the art algorithm)
- players A/B with $N_A$/$N_B$ neurons
- $P_{A\to B}\,$: probability that A beats B
$\hspace{10ex}
P_{A\to B} = \frac{1}{1+10^{(r_B-r_A)/400}}
= \frac{N_A}{N_A+N_B}
$
two player knapsack problem
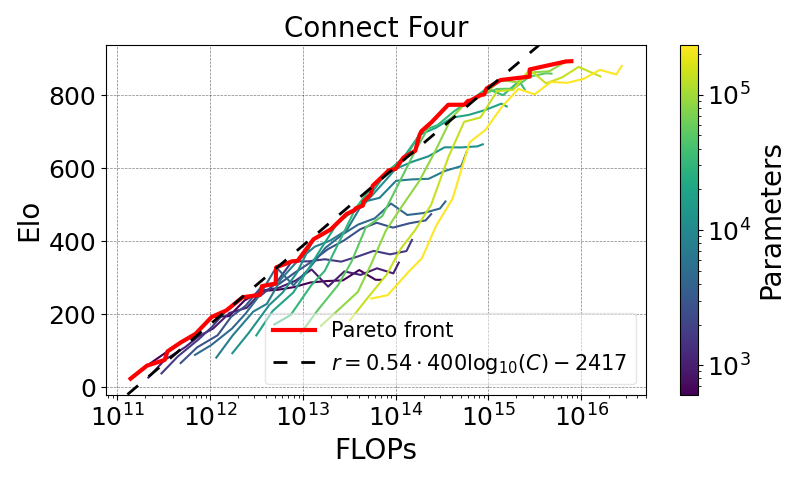
Connect 4 (and other games)
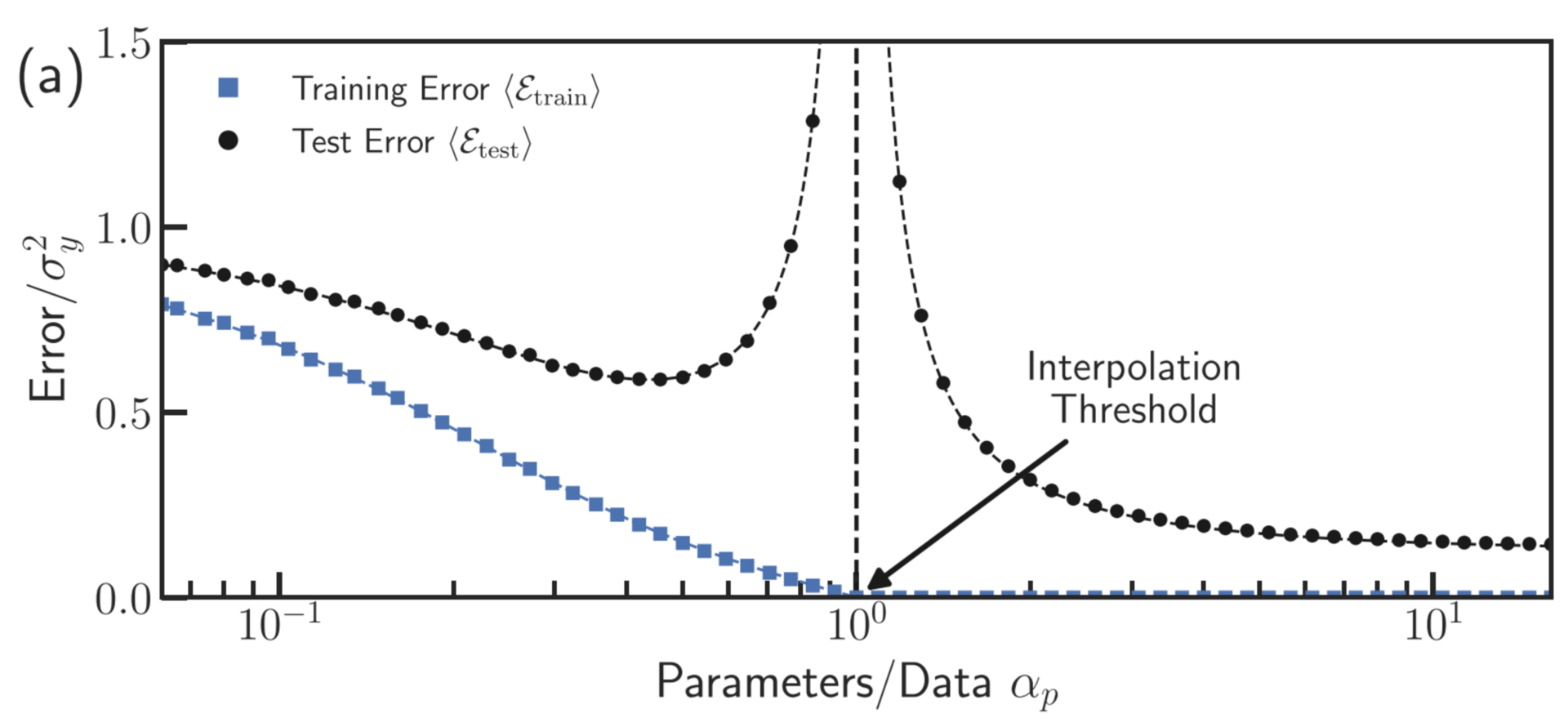
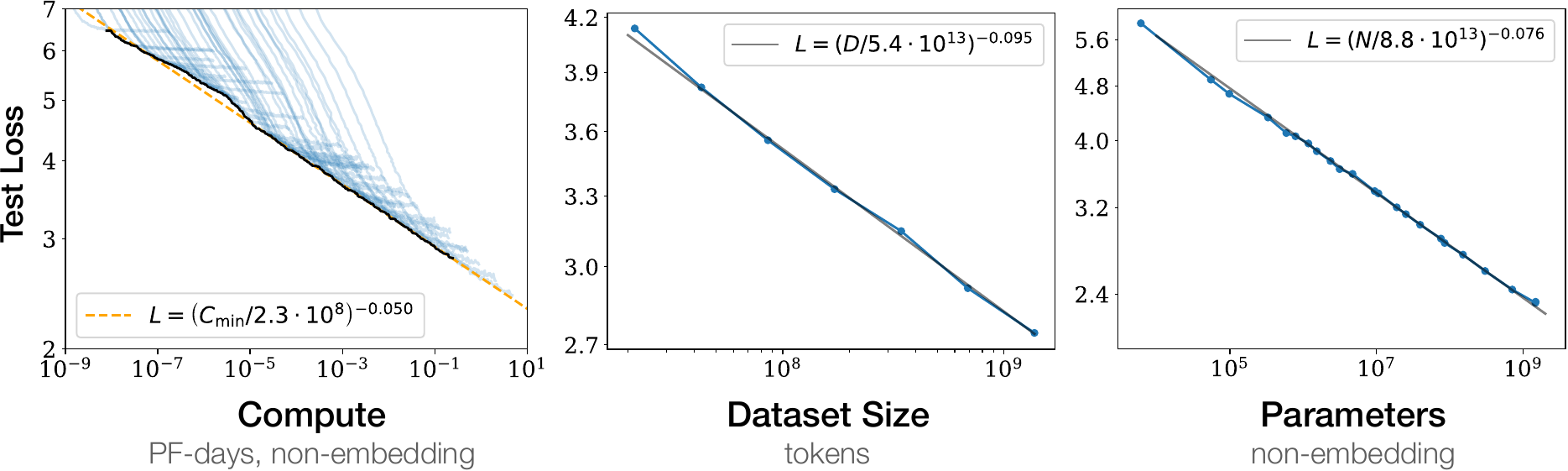
double descent
- test loss vs. training loss
- training loss $\ \ \langle {\cal E}_{\rm train}\rangle$
test loss $\ \ \langle {\cal E}_{\rm test}\rangle$
- idealized model
Rocks & Mehta, PRR 2022
fitting vs. generalizing
given enough parameters,
one can fit an elephant
- fitting an elephant $\neq$
fitting a giraffe
→ bad generalization
constrained overfitting
- constrained training, e.g.
:: synaptic weight regularization
:: dropout (removing small links)
- iterative gradient descent may lead to
:: implicit regularization
:: implicit sparsity (many weights are small/zero)
modern deep learning models work
in the regime of massiv overfitting
dropout
- removing links (units) randomly during training
:: all units need to contribute
:: more robust, generalizes better
- rescale by $\qquad \frac{1}{1-p}$
:: dropout rate $\ p\approx 0.1$
- no dropout during inference
#!/usr/bin/env python3
# dropout illustration
import torch
import torch.nn as nn
#torch.manual_seed(42) # manual seeding
dropout = nn.Dropout(p=0.5) # dropout layer instantiation
input_tensor = torch.arange(12.0).view((3,4)) + 1.0
dropout.train() # start training mode
output_train = dropout(input_tensor)
dropout.eval() # evaluation mode (no scaling)
output_eval = dropout(input_tensor)
print("\n# original tensor")
print(input_tensor)
print("\n# after Dropout in training mode (with scaling)")
print(output_train)
print("\n# after Dropout in evaluation mode")
print(output_eval)
mixture of experts (MoE)
AI generated illustration

- one big FFN → many small FFN
:: small FFN $\ \hat{=}\ $ expert
- routing mechanism for expert selection
:: separately for every token
- (learnable) gating vectors $\ \mathbf{g}_i$
:: for all experts $\ i$
- gating scores $\ a_i = \mathbf{g}_i\cdot\mathbf{x}$
:: token activity $\ \mathbf{x}$
- gating distribution $\ p_i = \mathrm{SoftMax}(a_i)$
:: select top-K experts
faster: for inference, only a subset of experts is needed