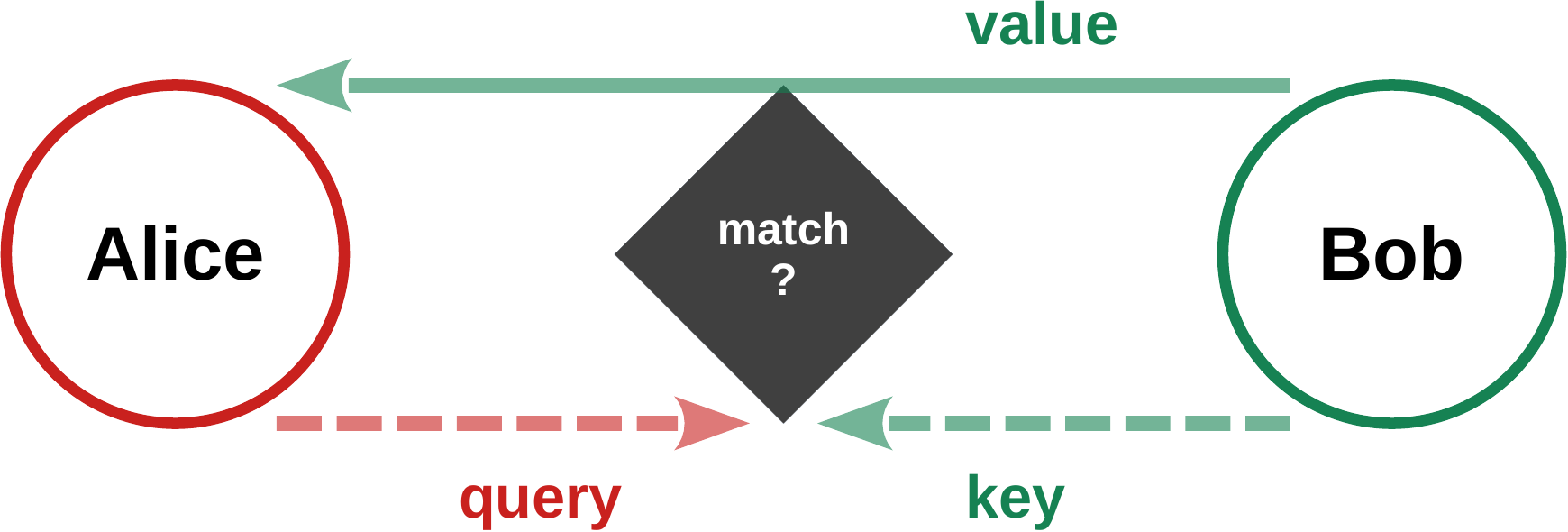
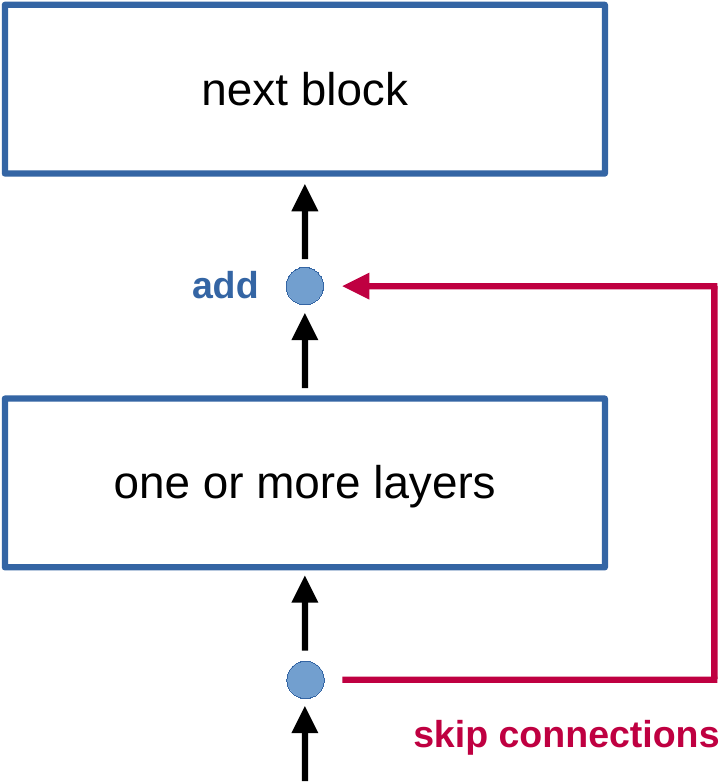
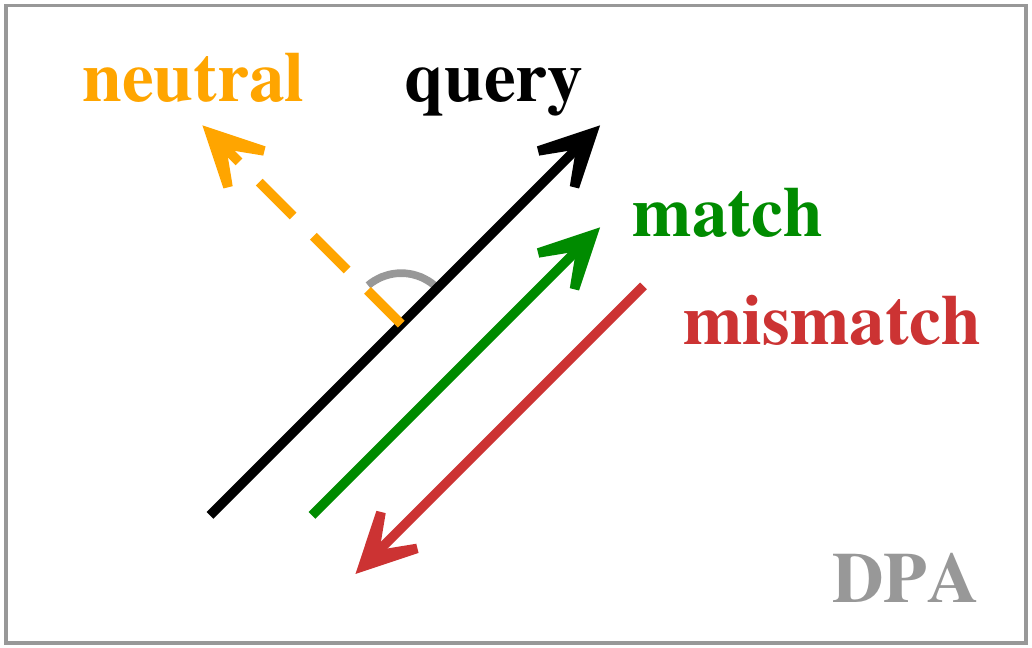
#!/usr/bin/env python3
# basic attention layer
# no batch processing, no layer norm
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
nLayer = 24 # number of layers
nContext = 24 # context length
dim = 2 # embedding dimension
nIter = 4000 # training iterations
learning_rate = 1.0e-3
# ==========================
# transformer bilayer module
# attention plus FFN
# ==========================
class transformerBilayer(torch.nn.Module):
def __init__(self, dim, nContext):
"""Q/K/V matrices will be broadcasted along the
context dimension
"""
super().__init__()
self.alpha = torch.zeros(nContext,nContext)
self.nContext = nContext # context length
self.dim = dim # embedding dimension
self.hidden = 4 # hidden layer expanded size
#
# Q/K/V matrices: requires_grad after scaline
#
mySigma = 0.1/(dim*dim)
self.Q_mat = mySigma*torch.randn(1,dim,dim)
self.K_mat = mySigma*torch.randn(1,dim,dim)
self.V_mat = mySigma*torch.randn(1,dim,dim)
self.Q_mat.requires_grad_(True)
self.K_mat.requires_grad_(True)
self.V_mat.requires_grad_(True)
#
# FFN: feed forward network
# FFN_1 --> hidden --> FFN_2
#
self.FFN_1 = torch.randn(1,self.hidden*dim,dim)*mySigma
self.FFN_2 = torch.randn(1,dim,self.hidden*dim)*mySigma
self.FFN_b = torch.randn(1,self.hidden*dim,requires_grad=True)
self.FFN_1.requires_grad_(True)
self.FFN_2.requires_grad_(True)
#
# padding mask for causal attention
#
self.paddingMask = torch.zeros(nContext,nContext) # for masking
for ii in range(nContext):
for jj in range(ii+1,nContext):
self.paddingMask[ii][jj] = -1.0e9 # exp -> 0
def FFN(self, x):
"""FFN sublayer
"""
# broadasting (1,.. ,.. ) --> (context,.. ,.. )
shape_1 = (self.nContext,self.hidden*self.dim,self.dim)
shape_2 = (self.nContext,self.dim,self.hidden*self.dim)
shape_b = (self.nContext,self.hidden*self.dim)
FFN_1_all = self.FFN_1.expand(shape_1)
FFN_2_all = self.FFN_2.expand(shape_2)
FFN_b_all = self.FFN_b.expand(shape_b)
#
xx = torch.einsum("chd,cd->ch",FFN_1_all,x)
hh = torch.tanh(xx+FFN_b_all)
yy = torch.einsum("cdh,ch->cd",FFN_2_all,hh)
return yy + x
def attention(self, x):
"""attention sublayer
"""
# broadasting (1,dim,dim) --> (context,dim,dim)
expanded_shape = (self.nContext,self.dim,self.dim)
Q_all = self.Q_mat.expand(expanded_shape)
K_all = self.K_mat.expand(expanded_shape)
V_all = self.V_mat.expand(expanded_shape)
# c and C: context (input length)
# d and D: dim (enbedding dimension)
QQ = torch.einsum("cdD,cD->cd",Q_all,x)
KK = torch.einsum("cdD,cD->cd",K_all,x)
VV = torch.einsum("cdD,cD->cd",V_all,x)
# normalized attention matrix
logits = torch.einsum("cd,Cd->cC",QQ,KK)
alpha = torch.exp(logits+self.paddingMask)
row_sum = alpha.sum(dim=-1, keepdim=True)
alpha = alpha / row_sum
# store detached attention matrix
self.alpha = alpha.detach()
# return with skip connections
return torch.matmul(alpha,VV) + x
def forward(self, x):
"""indexing always from the back
"""
x = self.attention(x)
x = self.FFN(x)
return x
def update(self, eps): # updating parameters
with torch.no_grad():
self.Q_mat -= eps*self.Q_mat.grad
self.K_mat -= eps*self.K_mat.grad
self.V_mat -= eps*self.V_mat.grad
self.Q_mat.grad = None
self.K_mat.grad = None
self.V_mat.grad = None
self.FFN_1 -= eps*self.FFN_1.grad
self.FFN_2 -= eps*self.FFN_2.grad
self.FFN_b -= eps*self.FFN_b.grad
self.FFN_1.grad = None
self.FFN_2.grad = None
self.FFN_b.grad = None
# ======================
# n-idential layer model
# ======================
allLayers = [transformerBilayer(dim,nContext) for iL in range(nLayer)]
def model(x):
for iLayer in range(nLayer):
x = allLayers[iLayer](x)
return x
# ====================================
# console printing of attention matrix
# ====================================
def printAttenionMatrix():
for iLayer in range(nLayer):
print()
print("# attention matrix for layer ", iLayer)
for ss in range(nContext):
for tt in range(nContext):
alpha = allLayers[iLayer].alpha[ss][tt]
print(f'{alpha:9.4f}', end="")
print()
# ======================
# standard loss function
# ======================
def lossFunction(outputActivity, targetActivity):
return torch.square(outputActivity - targetActivity).sum()
# ================================================
# training data, token at position i: x[i]
# x[i+1] = x[i] - x[i-1] (modulo normalization)
# settles into a limit cycle of period six
# initial warm-up is discarded
# ================================================
def trainingSequence(seqLength, myDim):
"""generates a random vector difference sequence"""
data = torch.zeros(2*seqLength,myDim)
data[0] = F.normalize(torch.randn(myDim), p=2, dim=0)
data[1] = F.normalize(torch.randn(myDim), p=2, dim=0)
for ss in range(2,2*seqLength):
vector_sum = data[ss-1]-data[ss-2]
data[ss] = F.normalize(vector_sum, p=2, dim=0)
return data[seqLength:] # discard warm-up phase
if (1==2):
testLength = 20
training_data = trainingSequence(testLength,dim)
print("# --- training_data ---")
for ll in range(testLength):
for dd in range(dim):
print(f'{training_data[ll][dd]:8.3f}',end="")
print()
# ===========================================
# training with random sequences
# token prediction == shifting prompt by (-1)
# ===========================================
print("# --- training ---")
for iIter in range(nIter):
training_all = trainingSequence(nContext+1,dim)
training_data = training_all[:-1]
training_value = training_all[1:]
loss = lossFunction(model(training_data),training_value)
if (loss<0.001):
break
loss.backward()
#
for iLayer in range(nLayer):
allLayers[iLayer].update(learning_rate)
if (iIter%200==0): # print progress
print(f'{iIter:4d} {loss.item():9.4f}')
#
# visual testing
#
test_all = trainingSequence(nContext+1,dim)
test_data = test_all[:-1]
test_value = test_all[1:]
yy = model(test_data)
print("# --- value vs. output ---")
for ll in range(nContext):
for dd in range(dim):
print(f'{test_value[ll][dd]:8.3f}',end="")
print(" |",end="")
for dd in range(dim):
print(f'{ yy[ll][dd]:8.3f}',end="")
print()
#
# print attention matrix
#
if (1==2):
print()
printAttenionMatrix()